Come usare Slither per trovare bug nei contratti intelligenti
Come usare Slither
Lo scopo di questo tutorial è mostrare come usare Slither per trovare automaticamente bug nei contratti intelligenti.
- Installazione
- Uso della riga di comando
- Introduzione all'analisi statica: Breve introduzione all'analisi statica
- API: Descrizione dell'API Python
Installazione
Slither richiede Python >= 3.6. Può essere installato tramite pip o usando docker.
Slither tramite pip:
pip3 install --user slither-analyzerSlither tramite docker:
docker pull trailofbits/eth-security-toolboxdocker run -it -v "$PWD":/home/trufflecon trailofbits/eth-security-toolboxL'ultimo comando esegue eth-security-toolbox in un docker che ha accesso alla tua directory corrente. Puoi modificare i file dal tuo host ed eseguire gli strumenti sui file dal docker
All'interno di docker, esegui:
solc-select 0.5.11cd /home/trufflecon/Eseguire uno script
Per eseguire uno script python con python 3:
python3 script.pyRiga di comando
Riga di comando rispetto a script definiti dall'utente. Slither è fornito con un set di rilevatori predefiniti che trovano molti bug comuni. Chiamare Slither dalla riga di comando eseguirà tutti i rilevatori, senza che sia necessaria alcuna conoscenza dettagliata dell'analisi statica:
slither project_pathsOltre ai rilevatori, Slither ha capacità di revisione del codice attraverso i suoi printer (opens in a new tab) e strumenti (opens in a new tab).
Usa crytic.io (opens in a new tab) per ottenere l'accesso a rilevatori privati e all'integrazione con GitHub.
Analisi statica
Le capacità e il design del framework di analisi statica Slither sono stati descritti in post del blog (1 (opens in a new tab), 2 (opens in a new tab)) e in un documento accademico (opens in a new tab).
L'analisi statica esiste in diverse varianti. Molto probabilmente ti renderai conto che compilatori come clang (opens in a new tab) e gcc (opens in a new tab) dipendono da queste tecniche di ricerca, ma è anche alla base di (Infer (opens in a new tab), CodeClimate (opens in a new tab), FindBugs (opens in a new tab) e strumenti basati su metodi formali come Frama-C (opens in a new tab) e Polyspace (opens in a new tab).
Non esamineremo in modo esaustivo le tecniche di analisi statica e i ricercatori qui. Ci concentreremo invece su ciò che è necessario per comprendere come funziona Slither, in modo da poterlo usare più efficacemente per trovare bug e comprendere il codice.
Rappresentazione del codice
A differenza di un'analisi dinamica, che ragiona su un singolo percorso di esecuzione, l'analisi statica ragiona su tutti i percorsi contemporaneamente. Per farlo, si affida a una diversa rappresentazione del codice. Le due più comuni sono l'albero sintattico astratto (AST) e il grafo del flusso di controllo (CFG).
Alberi Sintattici Astratti (AST)
Gli AST vengono usati ogni volta che il compilatore analizza il codice. È probabilmente la struttura più basilare su cui può essere eseguita l'analisi statica.
In breve, un AST è un albero strutturato in cui, di solito, ogni foglia contiene una variabile o una costante e i nodi interni sono operandi o operazioni del flusso di controllo. Considera il seguente codice:
1function safeAdd(uint a, uint b) pure internal returns(uint){2 if(a + b <= a){3 revert();4 }5 return a + b;6}L'AST corrispondente è mostrato in:
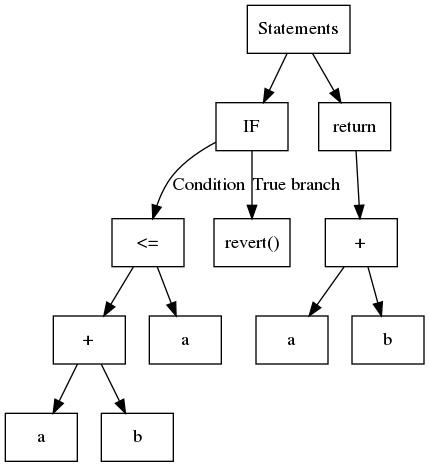
Slither usa l'AST esportato da solc.
Sebbene semplice da costruire, l'AST è una struttura annidata. A volte, non è la più semplice da analizzare. Ad esempio, per identificare le operazioni usate dall'espressione a + b <= a, devi prima analizzare <= e poi +. Un approccio comune è usare il cosiddetto pattern visitor, che naviga attraverso l'albero in modo ricorsivo. Slither contiene un visitor generico in ExpressionVisitor (opens in a new tab).
Il seguente codice usa ExpressionVisitor per rilevare se l'espressione contiene un'addizione:
1from slither.visitors.expression.expression import ExpressionVisitor2from slither.core.expressions.binary_operation import BinaryOperationType34class HasAddition(ExpressionVisitor):56 def result(self):7 return self._result89 def _post_binary_operation(self, expression):10 if expression.type == BinaryOperationType.ADDITION:11 self._result = True1213visitor = HasAddition(expression) # expression è l'espressione da testare14print(f'The expression {expression} has a addition: {visitor.result()}')Mostra tuttoGrafo del Flusso di Controllo (CFG)
La seconda rappresentazione del codice più comune è il grafo del flusso di controllo (CFG). Come suggerisce il nome, è una rappresentazione basata su grafi che espone tutti i percorsi di esecuzione. Ogni nodo contiene una o più istruzioni. Gli archi nel grafo rappresentano le operazioni del flusso di controllo (if/then/else, loop, ecc.). Il CFG del nostro esempio precedente è:
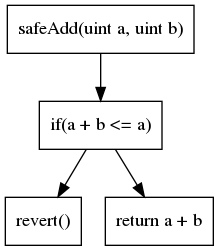
Il CFG è la rappresentazione su cui si basa la maggior parte delle analisi.
Esistono molte altre rappresentazioni del codice. Ogni rappresentazione ha vantaggi e svantaggi a seconda dell'analisi che si desidera eseguire.
Analisi
Il tipo più semplice di analisi che puoi eseguire con Slither sono le analisi sintattiche.
Analisi sintattica
Slither può navigare attraverso i diversi componenti del codice e la loro rappresentazione per trovare incongruenze e difetti usando un approccio simile al pattern matching.
Ad esempio, i seguenti rilevatori cercano problemi legati alla sintassi:
-
Shadowing delle variabili di stato (opens in a new tab): itera su tutte le variabili di stato e controlla se qualcuna fa ombra a una variabile di un contratto ereditato (state.py#L51-L62 (opens in a new tab))
-
Interfaccia ERC20 errata (opens in a new tab): cerca firme di funzioni ERC20 errate (incorrect_erc20_interface.py#L34-L55 (opens in a new tab))
Analisi semantica
A differenza dell'analisi sintattica, un'analisi semantica andrà più a fondo e analizzerà il "significato" del codice. Questa famiglia include alcuni ampi tipi di analisi. Portano a risultati più potenti e utili, ma sono anche più complessi da scrivere.
Le analisi semantiche vengono usate per i rilevamenti di vulnerabilità più avanzati.
Analisi delle dipendenze dei dati
Si dice che una variabile variable_a è dipendente dai dati di variable_b se esiste un percorso per il quale il valore di variable_a è influenzato da variable_b.
Nel seguente codice, variable_a è dipendente da variable_b:
1// ...2variable_a = variable_b + 1;Slither è dotato di capacità integrate di dipendenza dei dati (opens in a new tab), grazie alla sua rappresentazione intermedia (discussa in una sezione successiva).
Un esempio di utilizzo della dipendenza dei dati può essere trovato nel rilevatore di uguaglianza stretta pericolosa (opens in a new tab). Qui Slither cercherà un confronto di uguaglianza stretta con un valore pericoloso (incorrect_strict_equality.py#L86-L87 (opens in a new tab)) e informerà l'utente che dovrebbe usare >= o <= piuttosto che ==, per impedire a un utente malintenzionato di intrappolare il contratto. Tra le altre cose, il rilevatore considererà come pericoloso il valore di ritorno di una chiamata a balanceOf(address) (incorrect_strict_equality.py#L63-L64 (opens in a new tab)) e userà il motore di dipendenza dei dati per tracciarne l'utilizzo.
Calcolo del punto fisso
Se la tua analisi naviga attraverso il CFG e segue gli archi, è probabile che tu veda nodi già visitati. Ad esempio, se è presente un ciclo come mostrato di seguito:
1for(uint i; i < range; ++){2 variable_a += 13}La tua analisi dovrà sapere quando fermarsi. Ci sono due strategie principali qui: (1) iterare su ogni nodo un numero finito di volte, (2) calcolare un cosiddetto punto fisso (fixpoint). Un punto fisso significa fondamentalmente che l'analisi di questo nodo non fornisce alcuna informazione significativa.
Un esempio di punto fisso utilizzato può essere trovato nei rilevatori di rientranza: Slither esplora i nodi e cerca chiamate esterne, scritture e letture nello spazio di archiviazione. Una volta raggiunto un punto fisso (reentrancy.py#L125-L131 (opens in a new tab)), interrompe l'esplorazione e analizza i risultati per vedere se è presente una rientranza, attraverso diversi pattern di rientranza (reentrancy_benign.py (opens in a new tab), reentrancy_read_before_write.py (opens in a new tab), reentrancy_eth.py (opens in a new tab)).
Scrivere analisi usando un calcolo efficiente del punto fisso richiede una buona comprensione di come l'analisi propaga le sue informazioni.
Rappresentazione intermedia
Una rappresentazione intermedia (IR) è un linguaggio concepito per essere più adatto all'analisi statica rispetto a quello originale. Slither traduce Solidity nella propria IR: SlithIR (opens in a new tab).
Comprendere SlithIR non è necessario se si desidera solo scrivere controlli di base. Tuttavia, tornerà utile se si prevede di scrivere analisi semantiche avanzate. I printer SlithIR (opens in a new tab) e SSA (opens in a new tab) ti aiuteranno a capire come viene tradotto il codice.
Basi dell'API
Slither ha un'API che ti consente di esplorare gli attributi di base del contratto e delle sue funzioni.
Per caricare una base di codice:
1from slither import Slither2slither = Slither('/path/to/project')3Esplorare contratti e funzioni
Un oggetto Slither ha:
contracts (list(Contract): elenco dei contratticontracts_derived (list(Contract): elenco dei contratti che non sono ereditati da un altro contratto (sottoinsieme di contratti)get_contract_from_name (str): Restituisce un contratto dal suo nome
Un oggetto Contract ha:
name (str): Nome del contrattofunctions (list(Function)): Elenco delle funzionimodifiers (list(Modifier)): Elenco delle funzioniall_functions_called (list(Function/Modifier)): Elenco di tutte le funzioni interne raggiungibili dal contrattoinheritance (list(Contract)): Elenco dei contratti ereditatiget_function_from_signature (str): Restituisce una Function dalla sua firmaget_modifier_from_signature (str): Restituisce un Modifier dalla sua firmaget_state_variable_from_name (str): Restituisce una StateVariable dal suo nome
Un oggetto Function o Modifier ha:
name (str): Nome della funzionecontract (contract): il contratto in cui è dichiarata la funzionenodes (list(Node)): Elenco dei nodi che compongono il CFG della funzione/modificatoreentry_point (Node): Punto di ingresso del CFGvariables_read (list(Variable)): Elenco delle variabili lettevariables_written (list(Variable)): Elenco delle variabili scrittestate_variables_read (list(StateVariable)): Elenco delle variabili di stato lette (sottoinsieme di variables`read)state_variables_written (list(StateVariable)): Elenco delle variabili di stato scritte (sottoinsieme di variables`written)
Ultimo aggiornamento della pagina: 3 febbraio 2025


